

Новости шугнанского проекта
Студенты Школы лингвистики и Института классического Востока и античности в рамках студенческого проекта, поддержанного НИУ ВШЭ в 2020–21 г., запустили сайт, посвящённый шугнанскому языку, и шугнанский лингвистический корпус.
{kind=link}
{kind=link}
Участники проекта «Компьютерные и лингвистические ресурсы для поддержки шугнанского языка», поддержанного НИУ ВШЭ в 2020–21 г., запустили сайт, посвящённый шугнанскому языку, и шугнанский корпус.
Шугнанский язык принадлежит к восточноиранской группе иранских языков (индоевропейская языковая семья). Распространённый на востоке Таджикистана и на северо-востоке Афганистана, он является не просто языком шугнанцев, но и lingua franca памирских народов. По оценке Д. И. Эдельман, число носителей шугнанского – около 100 000 человек. На протяжении нескольких лет сотрудники Школы лингвистики проводили экспедиции на Памир для изучения шугнанского языка, однако в условиях пандемии внимание было сосредоточено на обработке уже имеющихся данных.
Памирские таджики и их многочисленные языки и диалекты, в силу своей вековой изолированности и обособленности, сохранили многие архаичные черты, и поэтому языковые, фольклорные и этнографические данные представляют большой научный интерес не только для иранистики, но также и для индоевропеистики, а в ряде случаев могут пролить свет на решение сложных и спорных вопросов исторического и этногенетического характера.
Первое упоминание о шугнанском языке и письменности на этом языке мы находим в записках китайского путешественника и монаха Сюана Цзана, который во второй четверти VII в. проходил через Ваханскую долину в Китай. Вот что он пишет: «письменность такая же, как в стране Духоло (т. е. в Тохаристане), а язык имеет отличия».
Тохир Каландаров
Институт этнологии и антропологии им. Н. Н. Миклухо-Маклая Российской академии наук
В 2020 г. участники проекта вычитали и разметили электронную версию самого большого словаря шугнанского языка, составленного Д. Карамшоевым. Выполнение этой трудной, но важной задачи позволило создать Telegram-бот и онлайн-словарь шугнанского языка (разработчик – Юрий Макаров), благодаря которым все желающие могут прикоснуться к памирской культуре.
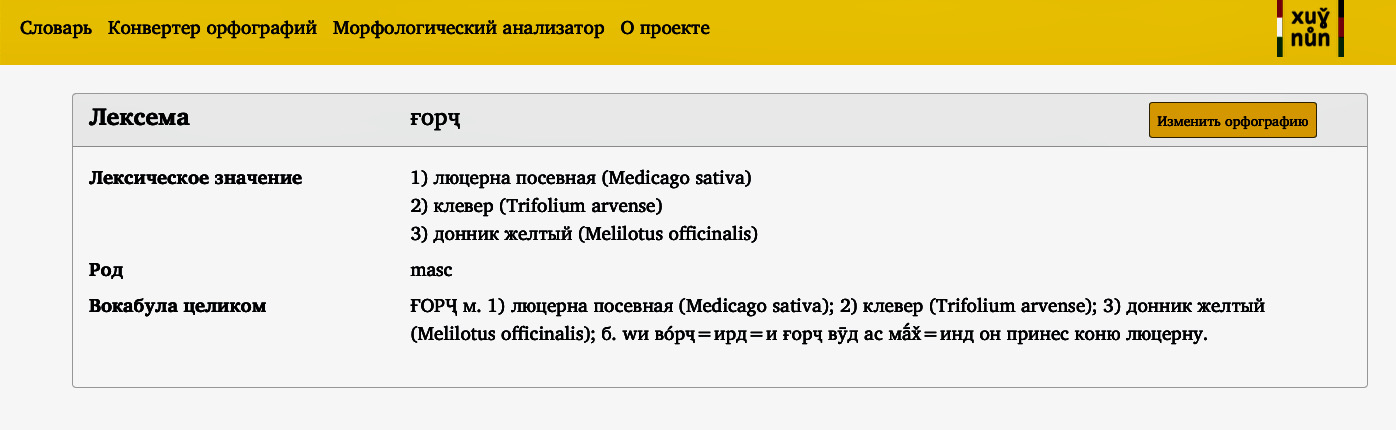
На сайте проекта также доступны инструменты обработки шугнанских текстов — конвертер орфографий и морфологический анализатор.
До 1937 г. на Памире, как пишут лингвисты А. Л. Грюнберг и И. М. Стеблин-Каменский, в школах использовалась нововведенная шугнанская письменность, однако в этом печально известном году она была отменена и ликвидирована.
Тохир Каландаров
Институт этнологии и антропологии им. Н. Н. Миклухо-Маклая Российской академии наук
Конвертер позволяет перевести большое количество текстов, записанных в разных шугнанских орфографиях, в принятую проектом латиницу. Это помогает унифицировать корпус текстов, в которых многие фонемы шугнанского языка зачастую передаются на письме по-разному.
Анализатор, используя электронную версию словаря Карамшоева, ищет в нём соответствия с токенами текста, а потом пытается подобрать подходящие аффиксы и клитики, обрамляющие найденный корень, в отдельном словаре морфем. На выходе пользователь получает морфемный разбор токенов текста: все слова, которые удалось разобрать, представляются в виде цепочек морфем (цепочек может быть несколько, если анализатор нашёл больше одной интерпретации). Сейчас идёт работа над системой «отсеивания» некорректных цепочек морфем. В будущем планируется добавление новых функций — например, выдачи значений сложных глаголов при их нахождении в тексте.
Разработкой обоих инструментов занимался Максим Меленченко, в создании анализатора помогали Фаина Даниэль и Юрий Макаров.
Пока шла разработка морфологического анализатора, конвертера орфографий и электронной версии шугнанского словаря, Александр Сергиенко искал новые шугнанские тексты.
А.Сергиенко:
Эта задача лишь кажется простой, ведь шугнанский язык часто называют бесписьменным. Нельзя просто так ввести в строке поиска «шугнанские книги» и сразу их скачать. Немногочисленные печатные издания на шугнанском доходили до нас окольными путями — с жёстких дисков шугнанских писателей, с которыми мы встречались в Хороге и Душанбе, от информантов, у которых были оцифрованные детские книги на шугнанском, из прошлых проектов ВШЭ.
 |
| Читальные залы Центра восточной литературы РГБ |
В 30-х годах было издано несколько шугнанских книг: буквари, учебники и переводы рассказов. Я отправился в Центр восточной литературы РГБ, где сфотографировал некоторые из этих изданий, а позднее оцифровал. Эти тексты были написаны очень непривычным алфавитом, и звуковое значение некоторых букв пришлось расшифровывать (совсем как в древних рукописях!), а потом переделывать систему автоматического распознавания текста с учётом этих данных. Несколько книг были написаны от руки, а потом напечатаны фотокопированием: в душанбинских типографиях 30-х годов нельзя было набрать символы вроде ā или ƣ.
После этого была вторая поездка, на этот раз в Санкт-Петербург. Там я пришёл в Публичную библиотеку, и библиотекарь на просьбу «Дайте мне шугнанский каталог» просто вернулся со стопкой книг, объяснив, что «Это все наши шугнанские книги, смотрите». Кроме того, меня пустили и в Институт восточных рукописей, где я поработал с архивом И. И. Зарубина.
В общем, в компьютерном проекте остаётся место и такой библиотечной романтике, раз уж экспедиционной романтики в этом году не получается.
В этом месяце также запущена начальная версия шугнанского корпуса.
Дмитрий Новокшанов, разработчик корпуса:
Корпус функционирует на базе платформы tsakorpus, созданной Т. А. Архангельским, и находится в стадии разработки. В настоящий момент устно-письменный он содержит четыре текста (три из которых представляют собой устные рассказы носителя), размеченные в ходе экспедиции в г. Хорог, общим объёмом в 1269 словоупотреблений.
Формат устного корпуса предполагает, что, помимо обычной работы с письменными текстами, исследователь может прослушивать их чтение носителями. Они были преобразованы из формата .eaf в .json с помощью встроенного в корпусную платформу конвертера. Тексты пока обладают только базовой метаразметкой: название текста, дата записи, автор и жанр/тип текста. Поиск по грамматическим значениям может быть осуществлен как по глоссам, так и по основным грамматическим категориям, которые приписываются отдельным словоупотреблениям. Несмотря на то, что работа над корпусом ещё не закончена, каждый желающий уже может получить базовое представление о шугнанском языке, а также послушать его носителей.
В планах – пополнение корпуса новыми текстами, унификация глосс, работа над распознаванием грамматических тегов и расширением метаданных.
Наконец, в ближайшее время запланирован выпуск русско-шугнанского и англо-шугнанского разговорника (автор – А. Сергиенко).
Следить за развитием проекта можно на странице https://ling.hse.ru/shughni, а также на сайте http://karamshoev.pythonanywhere.com/.